Mission Statement
Het datalab van het Stadslab Rotterdam heeft als doel:
“Making Human-Centered Sense of Data”.
Hier volgt de uitleg waarom binnen CMI een Human-centered (HC) Data-Lab wordt opgezet.
Data Deluge
De eerste vraag die opkomt is “Waarom wordt er juist nu zoveel nadruk gelegd op het omgaan & inzichtelijk maken van data?” en “Wat is data nu eigenlijk?”
Het antwoord hierop ligt besloten in de analoog naar digitale technologische-transitie die grote economieën wereldwijd hebben doorgemaakt vanaf de jaren 80 van de vorige eeuw. Momenteel bevinden we ons dan ook in periode van transitie: een datarevolutie (ter Louw, 2017; Schönberger & Cukier, 2013).
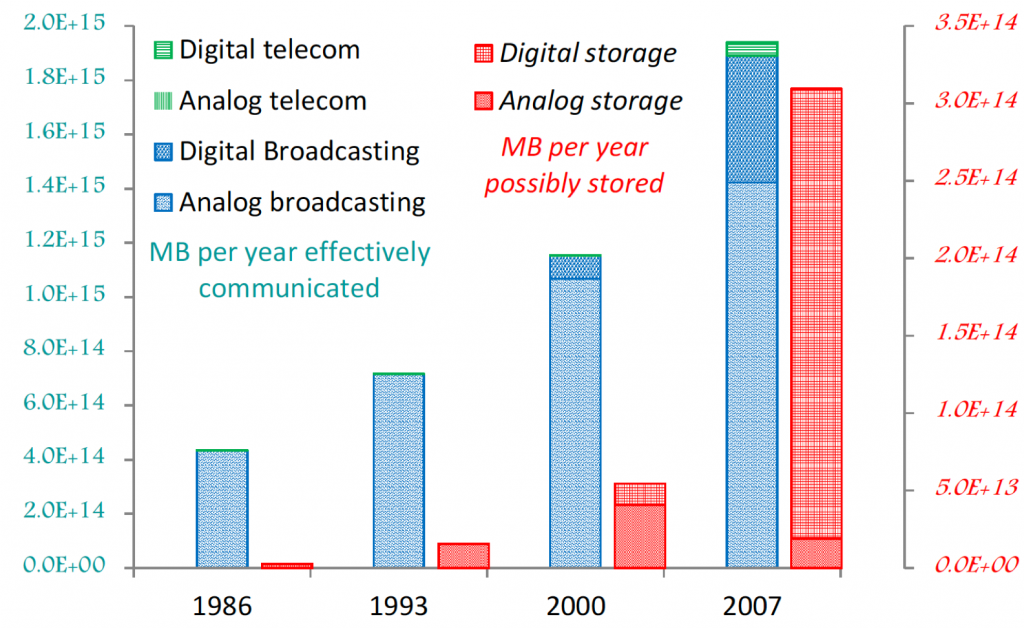
Dit fenomeen van de datarevolutie werd door Hilbert in 2011 aangeduid met de term “Data Deluge”:
De toename van de hoeveelheid digitaal beschikbare ongestructureerde/ruwe data overstijgt de totale hoeveelheid aan beschikbare “computer” rekenkracht. Dit gaat gepaard met het fenomeen dat er anno 2019 wereldwijd meer digitale data wordt geproduceerd dan analoge data (Hilbert, 2012).
In het engelstalige domein wordt deze transitie van mechanische en analoge elektronische technologie naar digitale technologie aangeduid met de term Digital Revolution of Third Industrial Revolution.
The Digital Platform Economy
Vijf technologische ontwikkelingen —sinds het begin van 21ste-eeuw—hebben geleid tot het Data Deluge fenomeen; deze vormen de oorsprong van de digitale platform economie.
{1} goedkopere en snellere computer-hardware, geheugen opslagcapaciteit & accucapaciteit—in de vorm van mobile devices, Internet -of-Things (IoT), wearables (Quantified-Self), Domotica, & Cyber Physical Systems (CPS) — in combinatie met
{2} laagdrempelige toegang tot Computer Software, Hardware & Artificial Intelligence (AI) zoals Numerical Analysis Software, Machine Learning (ML), Natural Language Processing (NLP) & Computer vision (CV), —in de vorm van Apps & Cloud Services—,
{3} kennisdeling via problem solving educational platforms & MOOCS / digital rights advocacy platforms / collaborative management tools & platforms / Social Media & Social networking platforms —in de vorm online multimediale educational platforms zoals Wikipedia, YouTube, Khan academy, MIT Opensourceware, Udemy, Udacity, Coursera, Wolfram Alpha / Bits of Freedom, OHCHR.org, Dig.Watch, AccessNow, Tactical technology Collective, Gendersec.tacticaltech.org / GitHub, Confluence, Drupal, Google Drive, Kahootz, Microsoft Office & Outlook, Trello, Slack, Yammer / Twitter, Instagram, Facebook, Whatsapp, LinkedIn, Yelp etc.—,
{4} data repositories —in de vorm van Data Directories zoals Statline (open databank van het CBS), Open Access Tracking Project (OATP), Wolfram data repository, OpenAI etc.—, en
{5} Cognitieve automatisering (CA) van handmatige, repetitieve administratieve processen met behulp van Robotic Process Automation (RPA). —in de vorm van op AI gebaseerde automatisering van taken met ‘analoge’, ongestructureerde data en subjectieve besluitvorming zoals het vastleggen van ongestructureerde IoT data, Classificatie van berichten en, Ondersteuning van besluitvorming—.
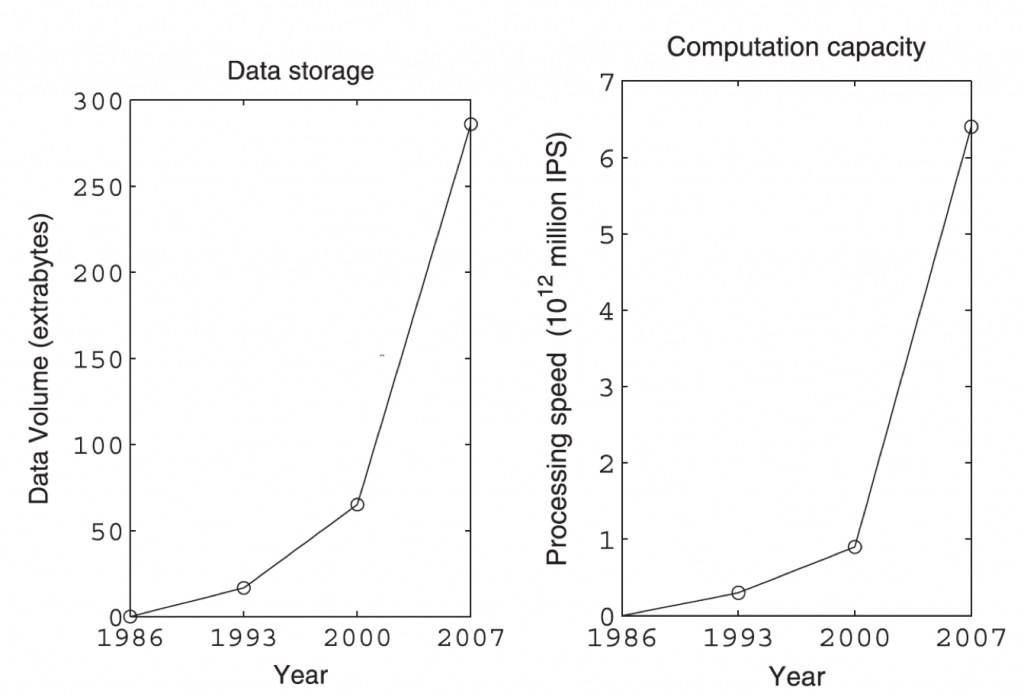
Zicht krijgen op de totale hoeveelheid beschikbare data die door mensen jaarlijks wordt geproduceerd is een complex vraagstuk. Een veel gebruikte methode is om het aantal beschikbare digitale devices te vermenigvuldigen met hun respectievelijke rekenkracht.
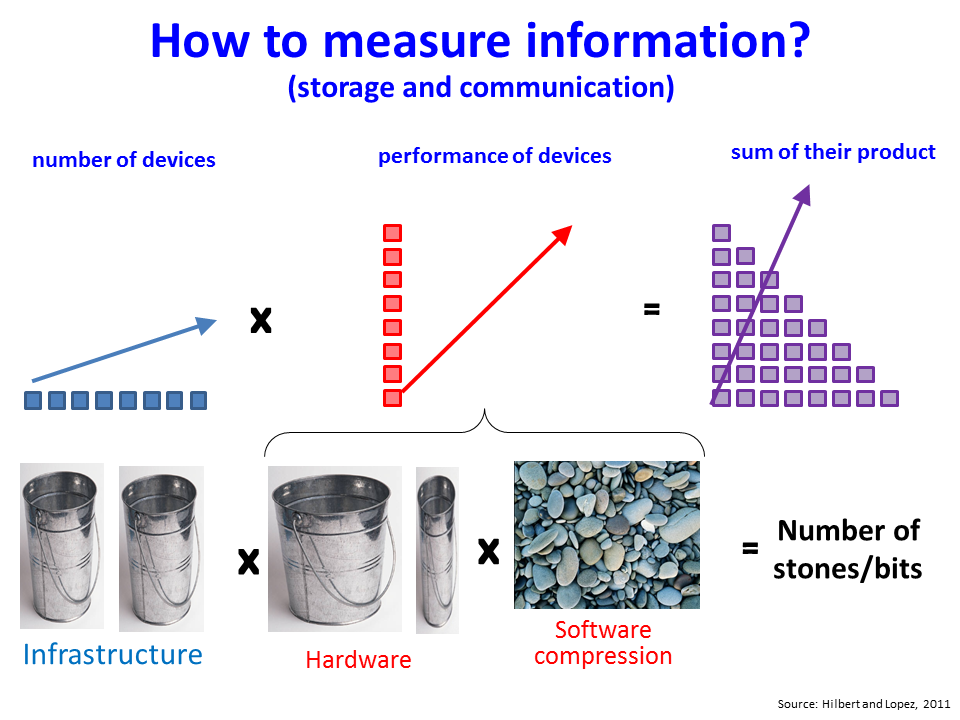
Hilbert et al. (2015) baseert zich op tellingen van de hoeveelheid data die men kan opslaan op de verschillende opslagmedia. Als er tien pagina’s tekst zijn en elke pagina bevat 1 kilobyte aan data, dan heb je dus 10 kilobyte aan data. Door dergelijke tellingen te doen voor 25 verschillende opslagmedia wereldwijd, ontstaat er een tijdreeks van de mondiale opslag van data tussen 1986 en 2014.
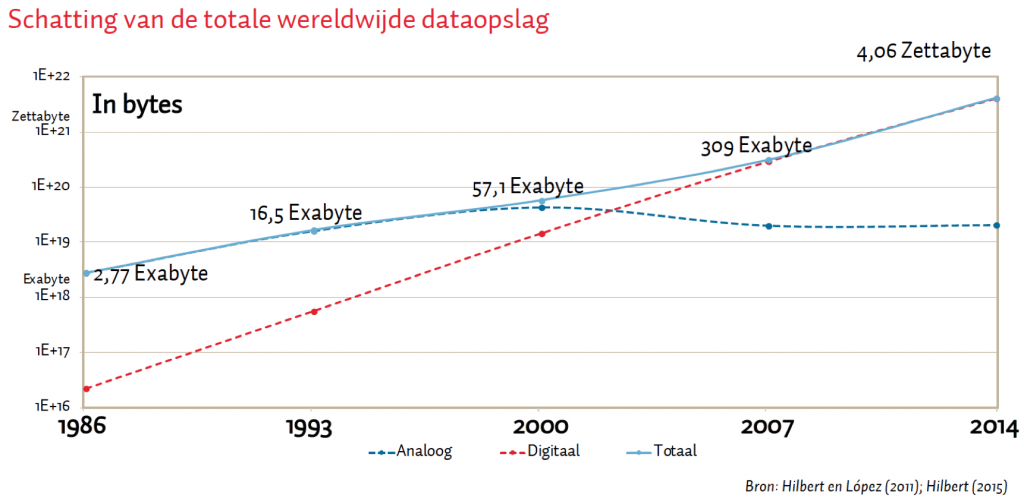
De dominantie van digitale dataopslag komt door de opkomst van digitale platforms rond 2005. Platformbedrijven hebben een grote invloed op onze economie en samenleving. Dat merkt iedereen die dagelijks het nieuws volgt, berichtjes uitwisselt, liedjes luistert, aankopen doet, online samenwerkt of werk zoekt. Juist de opkomst van “Flexwerken” het afgelopen decennium wordt toegeschreven aan het ontstaan van een Nederlandse platformeconomie.
Een digitaal platform is een online marktplaats waar gebruikers (vraag) en leveranciers (aanbod) elkaar rondom een geïntegreerd pakket van producten en cloud-diensten treffen.
Een voorbeeld van Nederlandse bodem is Shapeways: een succesvol digitaal platform dat on-demand 3D-printen faciliteert. Andere koplopers van Nederlandse origine zijn Academictransfer, Adyen, Blendle, Deliveroo, Funda, Galapagos, Marktplaats, Bol.com, Coolblue, Etsy, Peerby, Nu.nl, NRC.Next, Squla, TomTom, Tweakers, Wetransfer en Kieskeurig.nl.

Een digitaal platform kan disruptie in een reeds bestaande markt veroorzaken. Kenmerkend voor bedrijven die dergelijke platforms opzetten is dat ze vaak vele malen efficiënter, sneller of goedkoper zijn —zero marginal costs— dan vergelijkbare bedrijven in hun branche doordat Private Equity firma’s enorme bedragen investeren nog voordat er winst wordt gemaakt. Dit zijn niet noodzakelijkerwijs de meest innovatieve bedrijven. Zo zijn Bosch & LeddarTech anno 2019 het meest vergevorderd met de ontwikkeling van zelfsturende auto’s; daarbij gebruik makend van geavanceerde Lidar technologie. Tesla & Uber daarentegen, die zich vooral opstellen als een digitaal platform, worden gezien als het meest innovatief doordat zij via hun platform veel naamsbekendheid genieten en zo over veel geld kunnen beschikken.
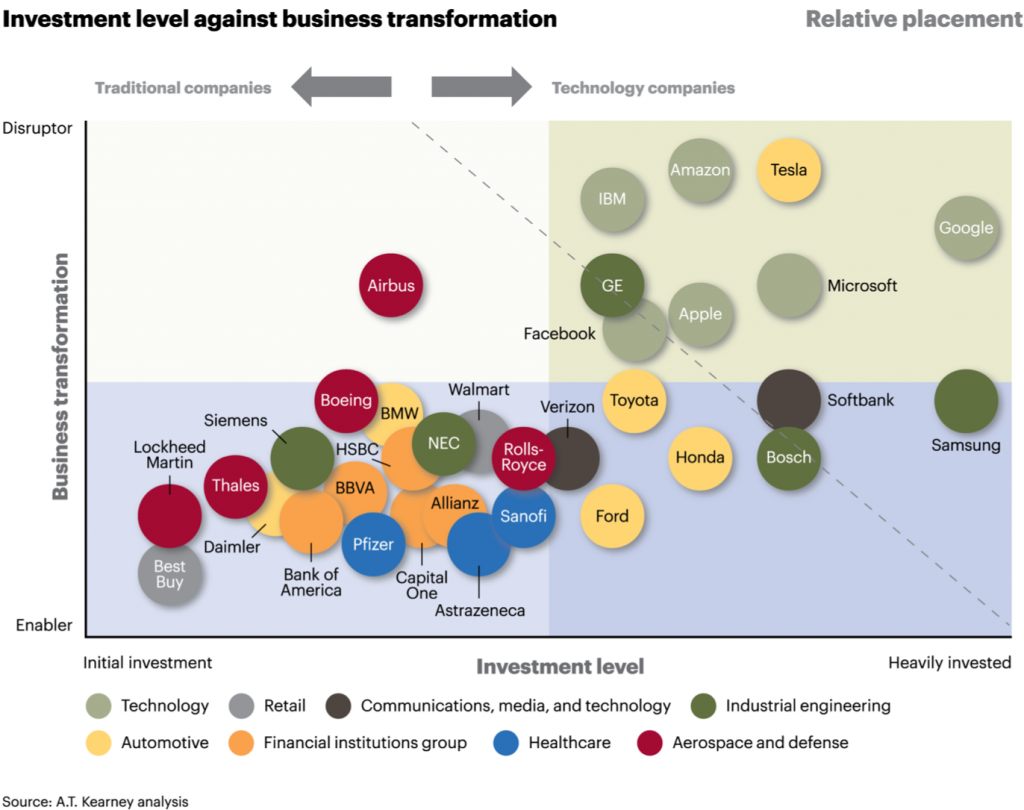
Gevolg is disruptie in bestaande marktverhoudingen doordat zij niet gebonden lijken/zijn aan de regelgeving die geldt voor het reeds bestaande bedrijfsleven dat afhankelijk is van technologie die alleen kan worden toegepast op industrieterreinen en/of afhankelijk zijn van fysieke winkels (Hu, 2018).
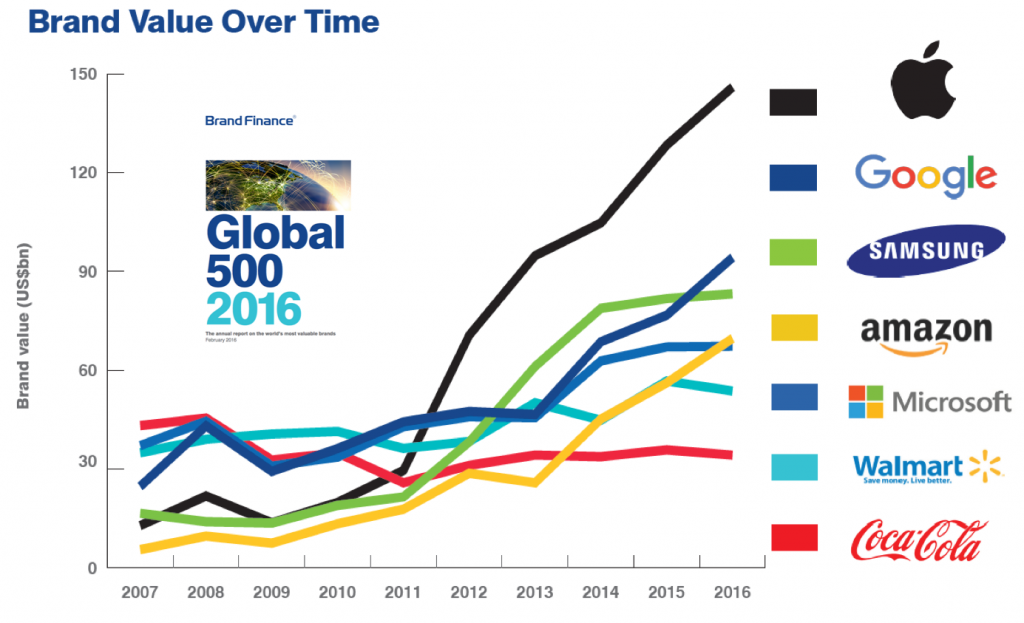
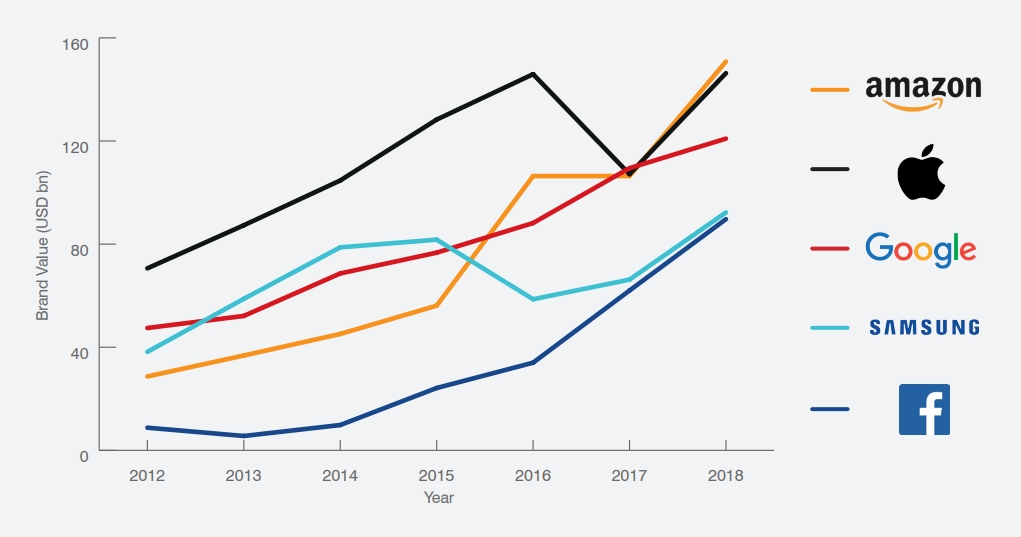
Er is vaak maar ruimte voor twee tot drie dominante platforms binnen een specifiek gebruikers domein, zoals Amazon, Alibaba, Apple, Baidu, Disney, Facebook, Google, Microsoft, Samsung, Spotify, Tencent & Netflix. Dit werkt in de hand dat veelbelovende start-ups of innovatieve marktleidende —maar veel kleinere— ondernemingen worden opgekocht door een dominant platform. Gevolg is een marktverstorende rem op innovatiekracht van (open)economieën die niet beschikken over dominante platforms. Desalniettemin, voor het eerst sinds het ontstaan van de platformeconomie zien we dat een dominant online streaming service —Netflix— serieus wordt bedreigt door een gevestigde-orde speler —Disney— die kan beschikken over veel geld, bestaande resources en naamsbekendheid. Tegelijkertijd neemt de marktwaarde van sterke merken zoals Coca Cola af, doordat ze geen optimaal gebruik (weten te) maken van een digitaal platform (MIT technological Review, 2017).
Big Data, IoT, Cloud Computing & the Human Factor
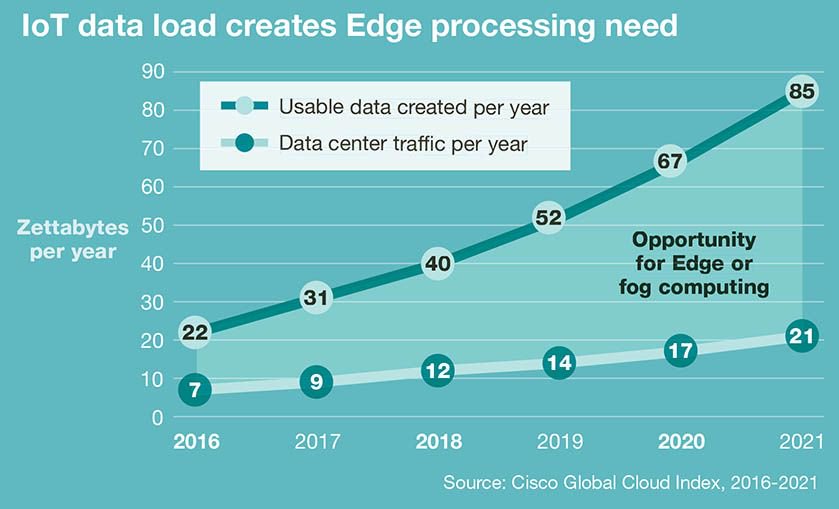
Het op grote schaal online verzamelen, verwerken en gebruiken van ongeordende, digitale data met behulp van computer algorithmen wordt veelal aangeduid met de term ‘big data’. De belofte van big data mining komt uit het combineren van zeer diverse databronnen om voor mensen nieuwe inzichten te creëren —data analytics— en verborgen waarde te ontsluiten (ter Louw, 2017). Volgens een schatting van Cisco (2018) zal in 2021 wereldwijd —250 ZettaBytes [ZB}— aan data worden gegenereerd, door mensen, machines en smart-devices. Echter deze data is kortstondig beschikbaar, slechts 10% —85 ZB— is bruikbaar voor verdere analyse. Hiervan kan slechts 9% —7,2 ZB–– daadwerkelijk worden opgeslagen. Opmerkelijk genoeg zal de hoeveelheid bruikbare data in 2021 het totale jaarlijkse dataverkeer —21 ZB— met een factor 4 overstijgen. Dus het fenomeen van de —Data Deluge— zal de komende jaren toenemen.
De menselijke rol wordt steeds verder verkleind in deze big data-driven digitale platform economie. Platform bedrijven vormen datacenters —Global Cloud Computing Platforms— die online data verwerken en/of combineren. Met andere woorden, Cloud computing is via het internet beschikbaar stellen van data, applicaties en/of hardware.
Er zijn drie verschillende servicemodellen van de cloud beschikbaar: Software as a Service (SaaS), Platform as a Service (PaaS) en Infrastructure as a Service (IaaS). Daarnaast bestaan er public, private, hybrid en community clouds, Dit zijn implementatiemodellen die de infrastructuur van de cloud inregelen. Deze modellen staan voor verschillen in bezit, beheer en ondersteuning van de infrastructuur. Azure van Microsoft & AWS van Amazon, zijn de dominante global Cloud Computing Platforms anno 2019. Daarnaast zijn Google Cloud Platform & IBM Softlayer, Oracle, Alibaba Stack-Up belangrijke opkomende cloud computing providers.
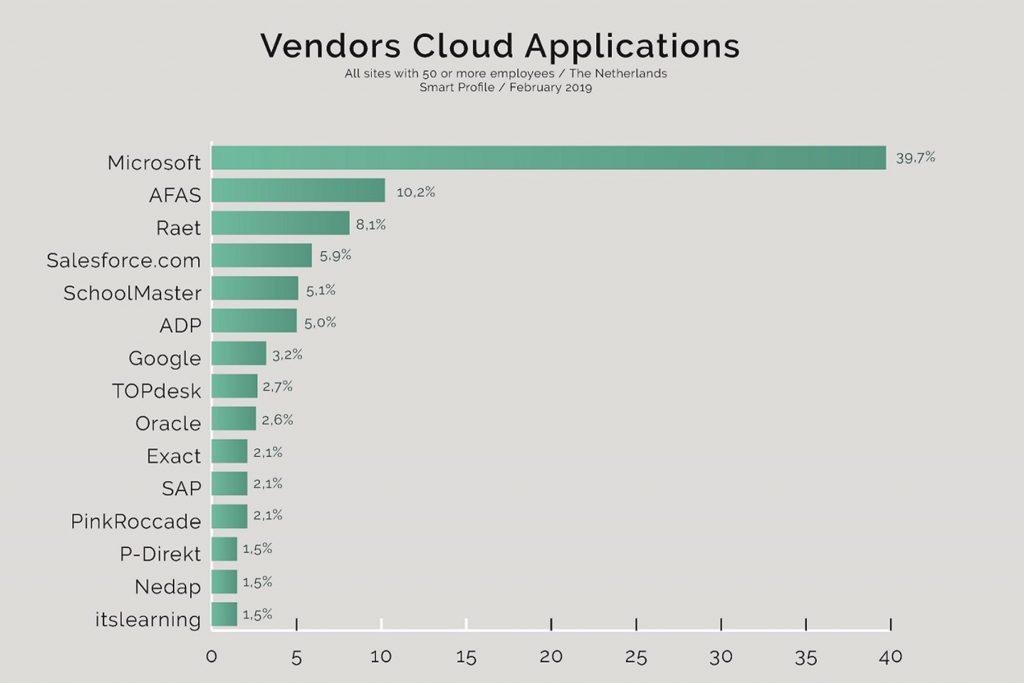
Daarnaast worden computer-algoritmen massaal ingezet om uit een grote hoeveelheid ongestructureerde data voor mensen interessante, betekenisvolle patronen/structuren te vinden. De beloftes van big data gaan vaak gepaard met een impliciete aanname dat big data processen zich onthechten van mensen. Sterker nog, de tussenkomst van menselijke handelen is ongewenst en wordt gezien als disruptief en inefficiënt.

De term Internet of Things (IoT) —vaak in één adem genoemd met big data— geeft het al aan: alledaagse voorwerpen kunnen zonder inmenging van de mens ongestructureerde data genereren en uitwisselen (Harbor Research, 2014).
Dat wil zeggen, fysieke of softwarematige sensoren leggen steeds meer data automatisch vast, systemen communiceren onderling zonder tussenkomst van mensen en zelflerende computer-algoritmes zijn beslissings- ondersteunend of lijken zelfs volledig autonoom beslissingen namens organisaties te nemen. In het geval van wearables & zelfsturende auto’s mag dat gewenst zijn. Vergaande automatisering van de cockpit in vliegtuigen kan desastreuze gevolgen hebben. Tenslotte, Machine-to-Machine (M2M) data communicatie door IoT smart-devices is een van de voornaamste oorzaken van de —Data Deluge— (Vermesan et. al., 2018).
In 2021 zal slechts 7,2 ZB kunnen worden opgeslagen en/of worden gebruikt voor verdere analyse op een totaal van 850 ZB.

Dat de dominantie van menselijk handelingen op het world-wide-web —the human factor— aan het afnemen is, blijkt uit het veranderde gebruik van Captcha’s. Dit is een methode voor spambeveiliging. Het doel is om interactieve websites te beschermen tegen misbruik door automatisch gegenereerde bijdragen te filteren.
Wat betekent captcha eigenlijk? Het acroniem staat voor —Completely Automated Public Turing test to tell Computers and Humans Apart—. In het Nederlands vertaald is een captcha dus een ‘geheel automatische openbare Turingtest om computers van mensen te onderscheiden’.
Methodes voor Human Verification die zijn gebaseerd op captcha’s kunnen grofweg worden verdeeld in tekst- en beeld-captcha’s, audio-captcha’s, reken-captcha’s, logica-captcha’s en gamification-captcha’s (Strato.nl, 2019). Maar die hinderlijke testjes vormen tegenwoordig voor menselijke gebruikers vaak een groter probleem dan voor de uitgekiende AI-based spamprogramma’s. Zulke spambots maken minder fouten dan mensen bij het oplossen van captcha’s (Google, 2014). Dit komt omdat Captcha’s een ideale tool zijn voor het trainen van AI toepassingen. Gevolg is dat Captcha’s steeds moeilijker zijn geworden voor mensen. Het blijkt dat mensen zeer slecht zijn in het oplossen van captcha’s in vergelijk met (Spam)Bots. Dit komt omdat mensen voortdurend fouten maken & gevoelig zijn voor ruis, culturele context, veranderingen in patronen zoals spraak- en/of gezichtsherkenning of risicoanalyse van zoiets als een gevaarlijke verkeerssituatie.
Information (Entropy), Bootstrapping, Bayesian Inference & Stationarity
Problematisch is dat het begrip data vaak wordt gekoppeld aan de term informatie. Deze relatie is echter niet zonder problemen. Dit wordt verstrekt door inzichten uit de fundamentele wetenschap dat de Fysische Wereld —onze werkelijkheid— niet begrepen moet worden in termen van ondeelbare kleine deeltjes (Dirac, 1933) maar in termen van informatie uitwisseling (Shannon, 1948). Dit communicatiemodel stelt informatie uitwisseling —Information Entropy— centraal als basiseenheid voor onze biologische & fysische werkelijkheid.
Informatie moet dan ook gezien worden als een maat voor gereduceerde onzekerheid. Zo bezien, heb je twee dingen nodig om informatie te creëren uit data: onzekerheid die voor mensen van belang is ––we gaan morgen zeilen, gaat het waaien?— en data dat de onzekerheid ongedaan kan maken —een weersvoorspelling—.
Deze relatie tussen data en het begrip informatie geeft inzicht in fenomenen als mens-machine interactie, kunstmatige intelligentie, bio-diversiteit, evolutie, klimaatverandering, donkere-materie, zwarte gaten en quantum computing (Verlinden, 2017).
De implicaties van informatie als basiseenheid waaruit onze werkelijkheid is opgebouwd zijn enorm. In de eerste plaats vormt het een verklaring waarom stationariteit ––de aanname dat natuurlijke fenomenen fluctueren binnen vaste grenzen van statistische onzekerheid onafhankelijk van tijd— een achterhaald concept is.
Voorspellingen als: “In Nederland vindt 1 keer op de 1000 jaar een overstroming plaats bij de huidige hoogte van de zeespiegel”; zijn niet meer houdbaar omdat door klimatologische veranderingen stationariteit eerder uitzondering is dan regel. Zo’n uitzondering is dat het KNMI gebruik maakt van 2de orde stationariteit voor het interpoleren van temperatuurgegevens om tot een weersverwachting van 5 dagen te komen (Salet, 2009).
Stationarity lijkt ook niet langer houdbaar voor door mensen vervaardigde interactieve & virtual reality (VR) technologie zoals wordt gebruikt in de ruimte & luchtvaart. Een goed voorbeeld hiervan zijn twee vliegtuigcrashes binnen een half jaar, met hetzelfde toestel. De ongelukken van de Boeing 737 MAX 8-toestellen van Lion Air en Ethiopian Airlines werden veroorzaakt door het nieuwe —automatische Maneuvering Characteristics Augmentation System (MCAS)—. Dat systeem was nodig omdat dit model grotere motoren heeft, waardoor de balans anders is. Hierdoor kan de neus gemakkelijk te ver omhoog gaan. Het heeft meerdere landen en ook reisconcern TUI doen besluiten in april 2019 om de Boeing 737 Max voorlopig aan de grond te houden.

De mens-machine interactie in de cockpit van dit passagiersvliegtuig was niet meer te voorspellen op basis van stationariteit omdat het design van de cockpit niet was aangepast op de veranderende specificaties van het vliegtuig zelf. De complexiteit van een modern vliegtuig vereist een hoog geautomatiseerde omgeving —de cockpit— vanwege de hoge mate aan onzekerheid bij de piloten hoe het vliegtuig te besturen bij wisselende omstandigheden wat “Shared Situational Awareness” in de weg staat. Dat wil zeggen, wanneer een machine taken overneemt van de mens dan is het moeilijk te voorspellen hoe —in geval de automatisering faalt— de mens-machine samenwerking zou moeten verlopen—shared control paradigma—.
Het gevolg is dat lange termijn weersvoorspellingen & complexe mens-machine interacties gebaseerd op statistische data niet meer stationair zijn. De mensheid zal anders met data moeten omgaan dan tot nu tot het geval is geweest om grip te blijven houden op technologische en klimatologische ontwikkelingen. Bootstrapping in combinatie Bayesiaanse —stochastische— data modellen lijken vooralsnog een veelbelovend alternatief voor stationaire —deterministische— data modellen (Gal, Islam, & Ghahramani, 2017).
Wat betekent dat stochastische —lees toevals— data? In de klassieke statistiek kan je alleen iets als toevalsveranderlijke definiëren als je een handeling herhaaldelijk kan uitvoeren. Je hebt bijvoorbeeld een muntstuk. Je weet niet of het een perfect muntstuk is, waarbij de kans op kop of munt gelijk is: p=0.5. Dus is de kans op kop onzeker. Statistisch gezien is alleen het ‘opgooien van een muntstuk’ stochastisch —afhankelijk van een toevalstreffer— want als je dit verschillende keren doet, zie je verschillende uitkomsten. Bayesiaanse statistiek zal zowel ‘het muntstuk gooien’ als de kans op munt als toevalstreffer beschouwen (Ikhebeenvraag.be, 2010).
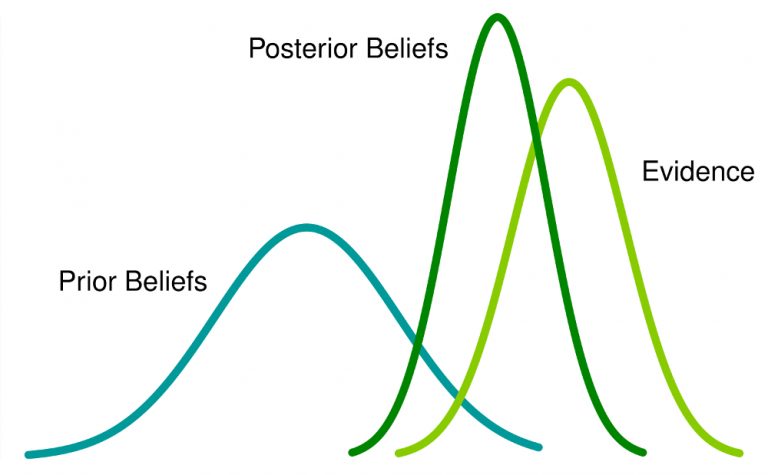
Bootstrapped Bayesiaanse analyse van data heeft het proces van gezichtsherkenning door camera’s —computer vision— aanmerkelijk verbeterd. Dat wil zeggen, beslissingen om niet eerder getoonde gezichten —posterior beliefs— te kunnen classificeren —-uit elkaar te houden— op basis van eerder geleerde gezichten —evidence— door zelflerende, autonome systemen zoals machine learning (ML) wordt mogelijk op basis van stochastische observaties. Dit zonder van te voren vastgelegde aannames —prior beliefs— over wat nu een gezicht eigenlijk is.
The AI arms race, AI Paradox & Singularity
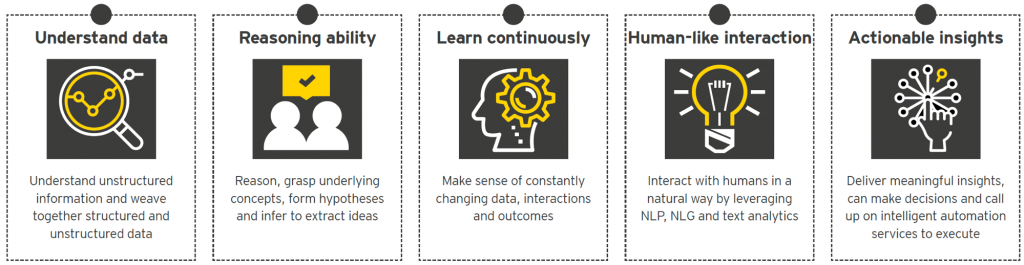
De verwachting is dat het antwoord op klimaatvraagstukken & complexe mens-machine interacties kan worden verkregen met behulp van IoT in combinatie met neurale netwerken die stochastische data als input gebruiken voor Natural Language Processing (NLP), Machine Learning (ML) en Computer Vision (CV).
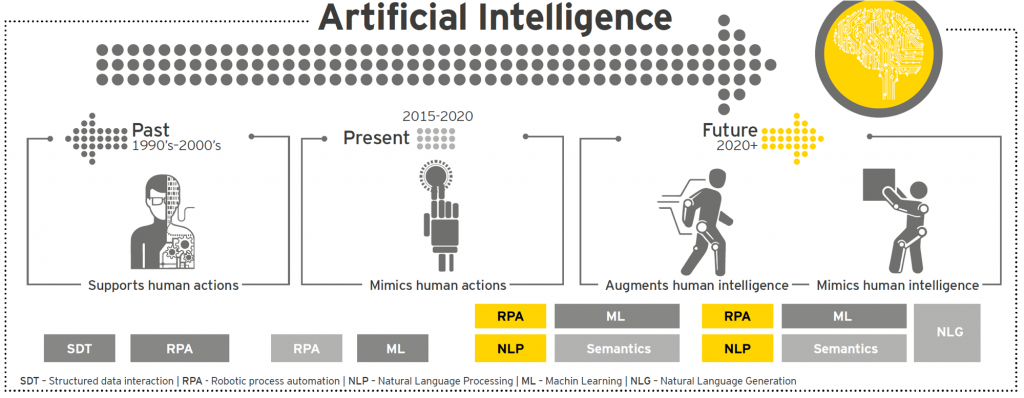
Deze Artificial Intelligence (AI) benadering zal de ontwikkeling mogelijk maken van data intensieve toepassingen zoals smart cities, klimaat modellen, zelf-rijdende auto’s, chatbots, semantic web search, block-chain, cognitive computing, biometric analysis, 3D-printing etc.
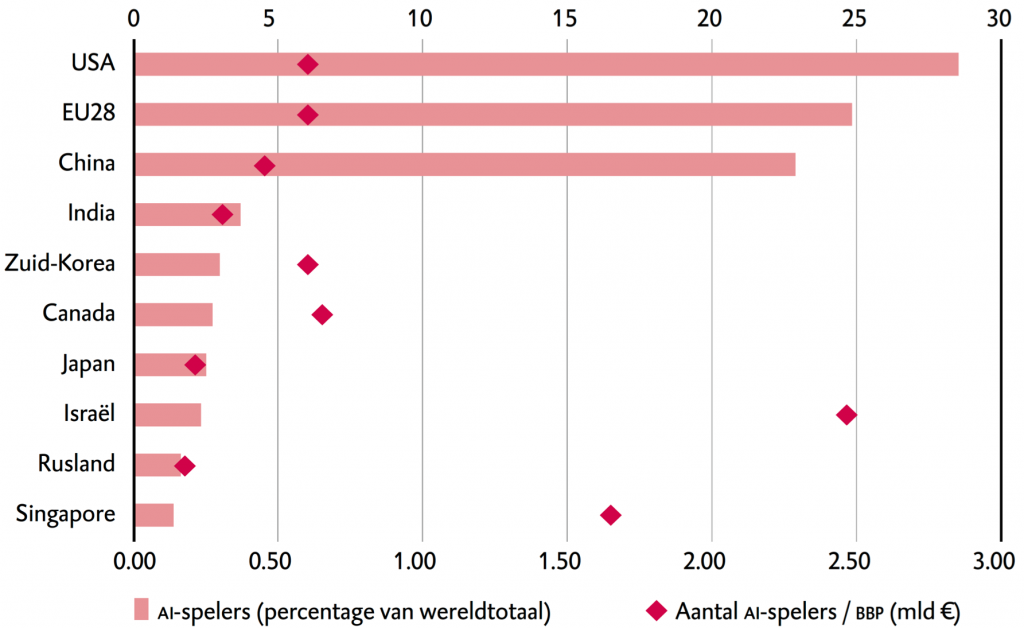
Deze AI belofte heeft een wereldwijde Big data race ontkend waarbij landen hun dominantie bepalen door de (i) hoeveelheid data die geanalyseerd kan worden en (ii) de snelheid waarmee dit gepaard gaat in combinatie met (iii) de mate waarin dit proces geautomatiseerd is. Zo gemeten zijn de U.S., China & Rusland koploper anno 2019. Europa daarentegen is minder dominant maar beschikt over relatief veel fundamentele kennis en een lange traditie van onderzoek naar AI. Daarnaast kent de EU als enige AI machtsblok een goed doordacht plan van aanpak voor het reguleren van persoonsgegevens en de bescherming ervan (GDPR). Door deze bescherming wordt de EU hierdoor aantrekkelijk als vestigingsplaats voor bedrijven en hoogopgeleide werknemers.
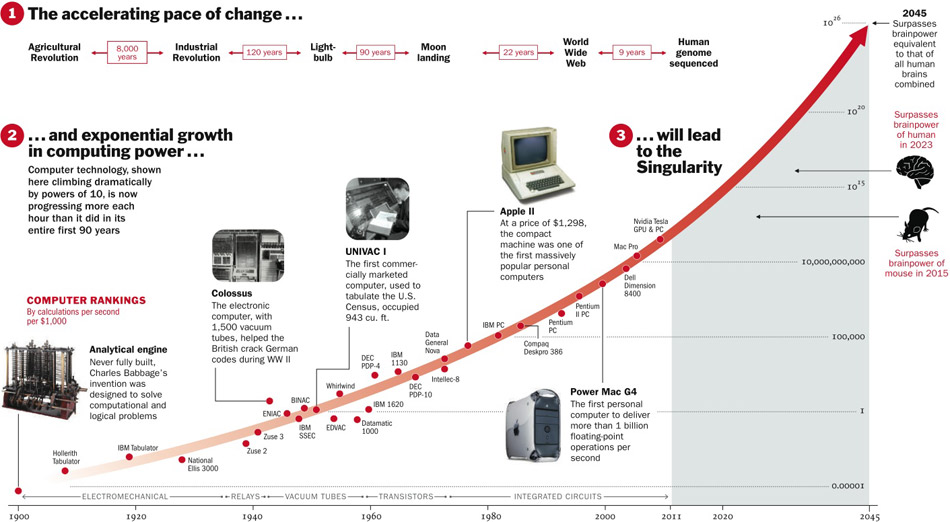
De schaduwkant van deze AI “wapenwedloop” is het ontstaan van singulariteit: dat we toestaan dat enkele monopolistisch digitale platforms —zoals Google & Facebook— alle data beheren om zo de samenleving te kunnen (be)sturen, met kunstmatige intelligentie zonder tussenkomst van de mens.

Dominante platforms kunnen singulariteit bereiken doordat ze via IoT- infrastructuur & cloud computing, big data verzamelen en zo op ongekende efficiënte wijze:
- {1} menselijk gedrag analyseren,
- {2} geavanceerde systemen op basis van kunstmatige intelligentie bouwen,
- {3} tot volledige automatisering/robotisering komen van taken met ‘analoge’, ongestructureerde data en subjectieve besluitvorming, en
- {4} allerlei diensten “gratis” of met grote kortingen aanbieden, in ruil voor persoonlijke data.
In 2016, beschreef het NRC deze vorm van singulariteit in een groot redactioneel artikel met als titel “Kunstmatige intelligentie gaat regeren”.
“Het lastige is dat de bedrijven ongetwijfeld zeer efficiënt zullen zijn in het aanbieden van al die diensten. Waarschijnlijk hebben burgers liever dat die bedrijven hun samenleving runnen dan de politici in wie ze sowieso al steeds minder vertrouwen hebben. Maar je kunt grote vraagtekens zetten bij de sociale gevolgen als bedrijven met technologie alle inefficiënties uit het systeem proberen te persen.“

Is het überhaupt een goed idee om data en kunstmatige intelligentie te gebruiken om de samenleving en de economie verregaand te automatiseren? Daarop klinkt de laatste tijd ook steeds meer kritiek. „De samenleving is geen machine die je zomaar kunt optimaliseren,” zegt de Duitse hoogleraar computationele sociologie Dirk Helbing (TU Delft, ETH Zürich).
Toch is de verwachting dat AI de mensheid in staat zal stellen om zich meer mens te kunnen voelen (MIT Review, 2017;Huffpost, 2017). In de literatuur wordt dit aangeduid met de term: The AI-Paradox.
European Data Protection Supervisor (EDPS) & the General Data Protection Regulation (GDPR)
Data in de vorm van persoonsgegevens als betaalmiddel voor cloud services en/of online content heeft een enorme vlucht genomen door de exponentiële groei van digitale platformen zoals Facebook en Google. Als reactie hierop heeft de EDPS —de Europese toezichthouder voor de gegevensbescherming: European Data Protection Supervisor— haar opinie gepubliceerd op het “Algemene Verordening Gegevensbescherming (AVG)/General Data Protection Regulation (GDPR)” wetsvoorstel van de Europese Commissie (EDPS, 2017). Deze opinie heeft grote gevolgen voor de businessmodellen van veel aanbieders van gratis apps, sociale platformen en andere diensten. De EDPS heeft een historisch overzicht vrijgegeven over het ontstaan van de GDPR:
De GDPR ziet toe op contracten voor de levering van “digitale inhoud” (Richtlijn 2015/0634). Het gaat hier niet alleen om digitale content —zoals films, muziek en apps–-, maar ook om digitale diensten —zoals social media platformen en Cloud Computing Services. Digitale content en/of diensten zijn vaak te gebruiken “free-of-charge”. In ruil daarvoor verwerken de aanbieders van deze content en/of diensten de persoonsgegevens van hun gebruikers. De Europese Commissie (EC) heeft voorgesteld om deze verstrekking van persoonsgegevens als een tegenprestatie voor een gratis content/dienst te reguleren. De verwachting is dat AI de consument kan helpen om zijn/haar persoonsgegevens te beschermen tegen het misbruik ervan (MIT Review, 2017;Huffpost, 2017).
Een ander fundamenteel aspect in relatie tot gegevensbescherming zijn —the right to be forgotten— & —the right to explanation— (Articles 21 & 22 of the GDPR). Deze artikelen benadrukken dat burgers —gebruikers van digitale platformen— uitleg verschuldigd is wanneer zij worden geconfronteerd met (zelflerende) computer-algoritmes die beslissings- ondersteunend zijn of zelfs volledig autonoom beslissingen nemen namens organisaties (Harnessing data & AI to reinvent customer engagement, 2018). Ongetwijfeld vormt de Brexit/Trump-Election Campaign/Facebook vs Cambridge Analytica episode uit 2016 en 2018 een tekstboek voorbeeld van een inbreuk op —the right to explanation–– in die zin dat dit bedrijf een -modern day propaganda machine representeert gebruik makend van —waponized AI—-
Benjamin Franklin once wrote that “pain is instructive”—
Adversarial Data & Natural Language Programming (NLP)
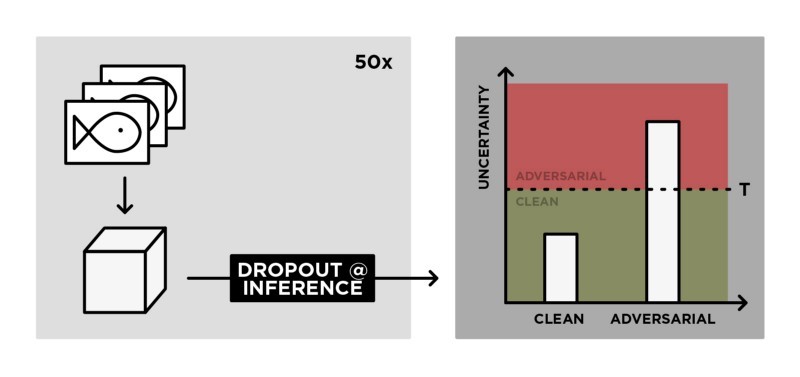
Een meer recent fenomeen in relatie tot AI singulariteit wordt ingegeven door zogenaamde Adversarial Examples —generative adversarial networks (GANs)— waarmee je realistisch uitziende gezichten kunt creëren die niet bestaan (Totta datalab, 2017).
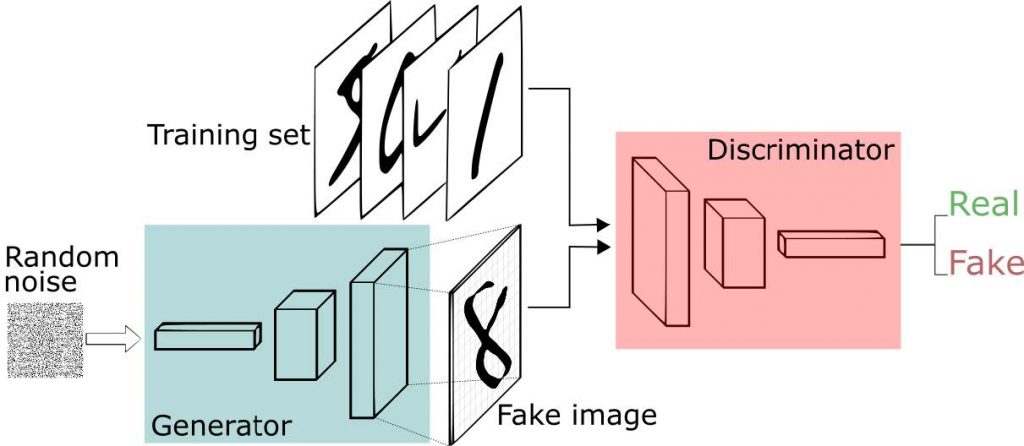
Adversarial als AI fenomeen begon met de lancering van Google DeepDream in 2015. Dit is een supervised Machine Learning (ML), data classificatie programma dat psychedelische output genereert van zo’n beetje alles. De data input doet er niet toe; de output is altijd creatief en origineel. De eerste stap is de selectie van bepaalde objecten —de input— die vervolgens worden geanalyseerd door het desbetreffende neurale netwerk. Nadat de patronen hierin zijn achterhaald door classificatie, worden er creatieve aspecten toegevoegd aan de input. De output is verbazingwekkend, doet denken aan kunst gemaakt door mensenhanden, en heeft dan ook weinig overeenkomsten met de originele input (the Verge, 2019).
Er worden fake eigenschappen toegevoegd en vermengd met de input; van bolle ogen tot kromme contouren. Deze visuele machine learning (ML) toepassing is vergelijkbaar met “Deep Fakes”: video en audio die nep is, maar nauwelijks van echt te onderscheiden; ook niet met behulp van AI (Computerworld.nl, 2018).
Een andere component van onbedoelde consequenties veroorzaakt door AI is het het gebruik van Natural Language Programming (NLP). Om AI ontvankelijk te maken voor taal is het noodzakelijk dat zelf-lerende systemen open en toegankelijk zijn. Dat vormt een zeer complex en moeilijk oplosbaar probleem, zoals uit de volgende voorbeelden zal blijken. Google Translate maakt bijvoorbeeld gebruik van een op NLP gebaseerde zelfontwikkelde taal om vertalingen te maken tussen twee talen die niet specifiek getraind zijn anders dan door de gebruikers ervan. Facebook heeft een NLP applicatie stopgezet die een eigen taal had ontwikkeld die voor mensen niet te begrijpen was (digital Journal, 2017).
Meer recent, heeft het natuurlijke taalmodel van OpenAI onder de naam GPT-2 —getraind met 40GB aan internetteksten, dat zelfstandig coherente teksten kan opstellen— voor ophef gezorgd (Computable.nl, 2019). Volgens OpenAI is het taalmodel in staat samenhangende en opvallend realistische tekstdocumenten te produceren zonder specifieke training. Het tumult ontstond niet alleen door de indrukwekkende resultaten, maar veeleer door het besluit van OpenAI om slechts een beperkte versie van GPT-2 vrijgegeven. Het oorspronkelijke model zou namelijk bezorgdheid opwekken over kwaadwillende toepassingen van de technologie, zoals het op grote schaal genereren van misleidende, bevooroordeelde of beledigende taal.
Dit fenomeen —unconscious bias— was ook de onderliggende reden dat Virtual Assistants zoals M van Facebook & Chatbots zoals Microsoft’s Tay voortijdig zijn gestopt omdat ze gevoelig bleken voor “adversarial examples” van gebruikers waardoor ze biased of ronduit racistisch werden (chatbotsmagazine, 2018; Wired, 2018;Arstechnica, 2016).
Meaningful Information, Digital Human Rights & Browser-Tracking
Voor het gebruik van data om informatief te zijn moet je de betekenis ervan kunnen duiden, oftewel de onderliggende semantiek moet herleidbaar zijn. Een telefoongids bestaande uit chinese characters zal voor de gemiddelde european niet informatief zijn —heeft geen semantische waarde omdat de characters geen herleidbare betekenis hebben— en dus slechts data bevatten.

Big data wordt dan ook ten onrechte als een technisch fenomeen getypeerd (Janssen, & van der Voort, 2017). De term ‘data’ geeft aanleiding tot misverstanden doordat het abusievelijk als substituut voor ‘informatie’ wordt gebruikt. In communicatie tussen mensen onderling bestaat een duidelijk onderscheid tussen {1} een Begrip (concept) dat bestaat in ons brein, {2} een Symbool (woord/teken/”sign”) dat ernaar verwijst en, {3} het Ding (fysiek of denkbeeldig object).
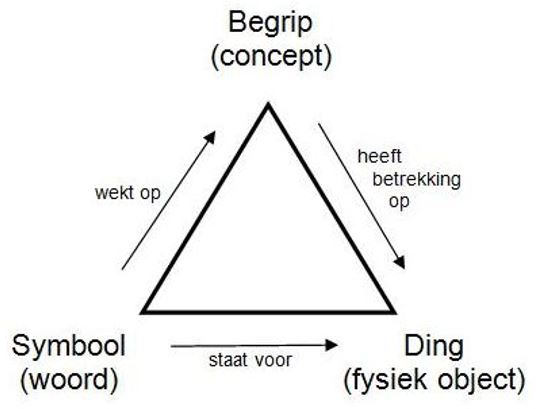
Computers beperken zich voornamelijk tot de opslag, verwerking en uitwisseling van uitsluitend tekens —lees data— zoals binaire getallen. Vooralsnog kunnen alleen mensen betekenis geven aan concepten —lees ideeen— doordat ons brein een voor mensen logisch navolgbare relatie legt tussen het teken, enerzijds, en een tastbaar object in de wereld om ons heen, anderzijds. Zo zal de betekenis van criminaliteitsdata per individu verschillen. Wanneer je fiets is ontvreemd, ben je alleen geïnteresseerd in data over gestolen fietsen. Echter geregistreerde criminaliteitsdata gaan voornamelijk over inbraken & beroving omdat daar proces verbaal voor wordt opgemaakt. De geregistreerde criminaliteit daalt al sinds 2002, zo blijkt uit cijfers van het Centraal Bureau voor de Statistiek (Statline: OpenData.CBS, 2019).
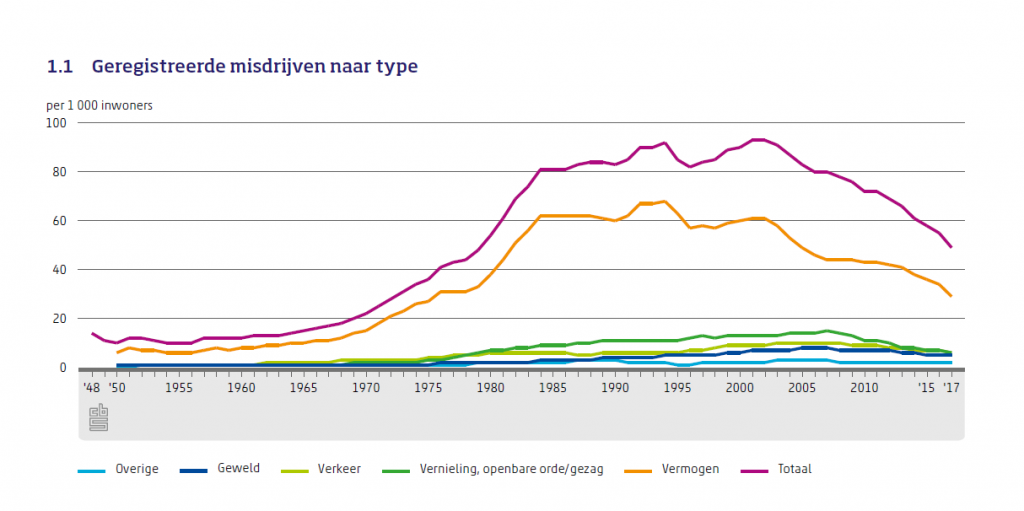
Maar hoe kan de doorsnee burger weten of de data alle criminaliteit omvatten? Immers, veel lichte misdaden en overtredingen worden niet gemeld en dus niet geregistreerd of zelfs uit politiek opportunistische redenen weggelaten in rapportages. Zo heeft staatssecretaris Harbers onlangs erkent dat het niet de bedoeling was om cijfers over criminaliteit onder asielzoekers “onduidelijk” te vermelden in de rapportage vreemdelingenketen: meer reguliere migratie, daling asielinstroom (Ministerie van Justitie en Veiligheid, 2019).
Om de burger te beschermen tegen de willekeur van informatieverstrekking door de Nederlandse overheid is de Wob in 1980 ingevoerd: de Wet openbaarheid van bestuur regelt het recht op informatie van de overheid. Deze regeling is een uitvloeisel van het uitgangspunt vastgelegd in de Grondwet wat luidt: “De overheid betracht bij de uitvoering van haar taak openbaarheid volgens regels bij de wet te stellen.” (Wob.nl, 2019). Doel van de Wob is om burgers in de gelegenheid te stellen de bestuurlijke besluitvormingsprocessen in het heden en verleden te doorzien. Dit ten behoeve van controle op een goede en democratische bestuursvoering. Misbruik van de Wob komt echter regelmatig voor (Poelman, 2014). In de praktijk blijken vooral onderzoeksjournalisten serieus gebruik te maken van de Wob (Keur, 2018).
Bits for Freedom heeft in 2018 een online tool beschikbaar gesteld — My data done right — waarmee gebruikers hun gegevens kunnen opvragen bij bedrijven, instellingen en de overheid. Die zijn verplicht inzage te geven volgens de AVG. Bits of Freedom is een onafhankelijke, digitale-burgerrechtenorganisatie van Nederlandse bodem, die opkomt voor digitale burgerrechten, Zij verdedigt met enig succes het grondrecht op privacy en het grondrecht op communicatievrijheid van de Nederlandse burger. Een voorbeeld hiervan is de campagne van Bits of Freedom rondom het raadgevend referendum over de Wet op de inlichtingen- en veiligheidsdiensten 2017, oftewel de ‘Sleepwet’ genaamd “Waar trek jij de grens?”.
Een jaar geleden (2017) werd #MeToo ongekend populair. Het bleek geen hype, maar een beweging die de verhouding tussen vrouwen en mannen blijvend op scherp zet. Het bewustzijn van mannen dat ze misschien een grens over kunnen gaan bij vrouwen, ook al bedoelen ze dat niet altijd zo, is vergroot. Het fenomeen van de MeToo-beweging lijkt direct voor te komen uit de opgang van digital human rights defenders zoals Bits of Freedom en DigRight die met name streven naar bescherming van de LGBT+-gemeenschap (Trouw, 2018). Het is dus bij uitstek een voorbeeld van de AI paradox. Immers #MeToo is groot geworden door Twitter, een AI-based digital platform waarmee gebruikers korte berichtjes van maximaal 280 tekens publiceren. Het is een sociaal medium waar mensen op elkaar kunnen reageren en elkaar kunnen volgen. Veel politici, artiesten, sporters en andere mediafiguren hebben een Twitteraccount. Een Twitterbericht heet een tweet.
Precies dát is de kracht van de beweging, zegt publicist en journalist Hasna El Maroudi, die onder meer schrijft over feminisme. “Het taboe op seksueel geweld is voor een deel weg. We kunnen het er over hebben, dat is winst voor mij.”
De beweging heeft ook schaduwkanten, voegt Te Brake daar aan toe. “Het is een soort openlijke rechtbank geworden. Ik ga ervan uit dat alle beschuldigingen waar zijn. Maar dan nog: veronderstelde daders zijn zonder deugdelijk onderzoek veroordeeld en hebben hun baan verloren.”
LGBT is een van oorsprong Engelse afkorting die staat voor lesbian, gay, bisexual, transgender. Lesbian betekent lesbische vrouw (homoseksuele vrouw), gay betekent homoseksuele man (of vrouw), bisexual betekent biseksueel persoon en transgender betekent transgenderpersoon (Amperanders.nl, 2019;NOS.nl, 2019). Dit is een zeer kwetsbare groep omdat in veel landen zij actief vervolgd worden; meestal op basis van een digitaal data spoor dat zij achterlaten door gebruikmaking van het world-wide-web. Dit brengt ons op het fenomeen van digital Browser Tacking: de vraag wie verzameld onze data, hoe en waarom als we ons op het internet begeven via het world-wide-web, dat wil zeggen, wanneer we gebruik maken van search engines zoals Google & Qwant, sociale media zoals Twitter & Instagram en digitale platforms zoals Azure & AWS.
Je kent het waarschijnlijk wel: je gaat online op zoek naar een hotel in Parijs en in de dagen daarna word je op allerlei websites bestookt met aanbiedingen voor Parijse hotels. Welkom in de wondere wereld van tracking. In een reeks artikelen bespreken we wat tracking precies is, hoe het werkt en wat je ertegen kunt doen.
Het samenstellen van een individueel digitaal spoor gebeurt vooral door browser tracking: Als je een website in je browser opent, maakt je browser verbinding met de webserver waarop de website wordt gehost. Als de website een extern onderdeel bevat, maakt je browser ook verbinding met de webserver van de leverancier van dat externe onderdeel. Die leverancier kan dit laten registreren door een trackingbedrijf en weet zo dat jij de oorspronkelijke website bekeek. Het kan er zelfs voor zorgen dat dezelfde hotelkamer boeking in prijs verschilt per persoon omdat trackingbedrijven een persoonlijk profiel maken op basis waarvan ze je inkomen inschatten en dus de waarschijnlijkheid dat je met een hogere prijs akkoord gaat (Myshadow.org, 2019). Hetzelfde geldt voor een identieke zoekopdracht uitgevoerd door dezelfde zoekmachine. Jouw persoonlijke zoekgeschiedenis en online aanlopen bepalen wat de zoekmachine als eerste laat zien en welke advertenties je te zien krijgt.
Laten we een voorbeeld nemen. Sommige webpagina’s bevatten één of meer YouTube-filmpjes. Die YouTube-filmpjes zijn externe —embedded— onderdelen die gehost worden op de webserver van YouTube. Als je dus een website met een YouTube-filmpje bezoekt, vraagt je browser dat filmpje op bij YouTube. Op die manier kan YouTube zien dat jij de bewuste webpagina bezoekt.
Trackers zijn ook externe onderdelen. Als een website een tracker van een trackingbedrijf bevat, maken alle bezoekers van die website verbinding met de webserver van dat trackingbedrijf. Zo weet het trackingbedrijf dus wie die website allemaal bezoekt. Veel websites bevatten trackers van dezelfde trackingbedrijven. Dat stelt die trackingbedrijven in staat internetters op al die websites te volgen.
Trackers hebben verschillende ‘verschijningsvormen’. Bijvoorbeeld als advertentie. Vaak gaan websites niet zelf op zoek naar adverteerders, maar besteden dat uit aan advertentiebedrijven. De meeste advertenties op websites zijn dus externe onderdelen die geleverd worden door advertentiebedrijven. Om advertenties zo goed mogelijk af te stemmen op een websitebezoeker, moeten advertentiebedrijven iedere bezoeker kunnen herkennen en analyseren. Dat doen ze door je te tracken.
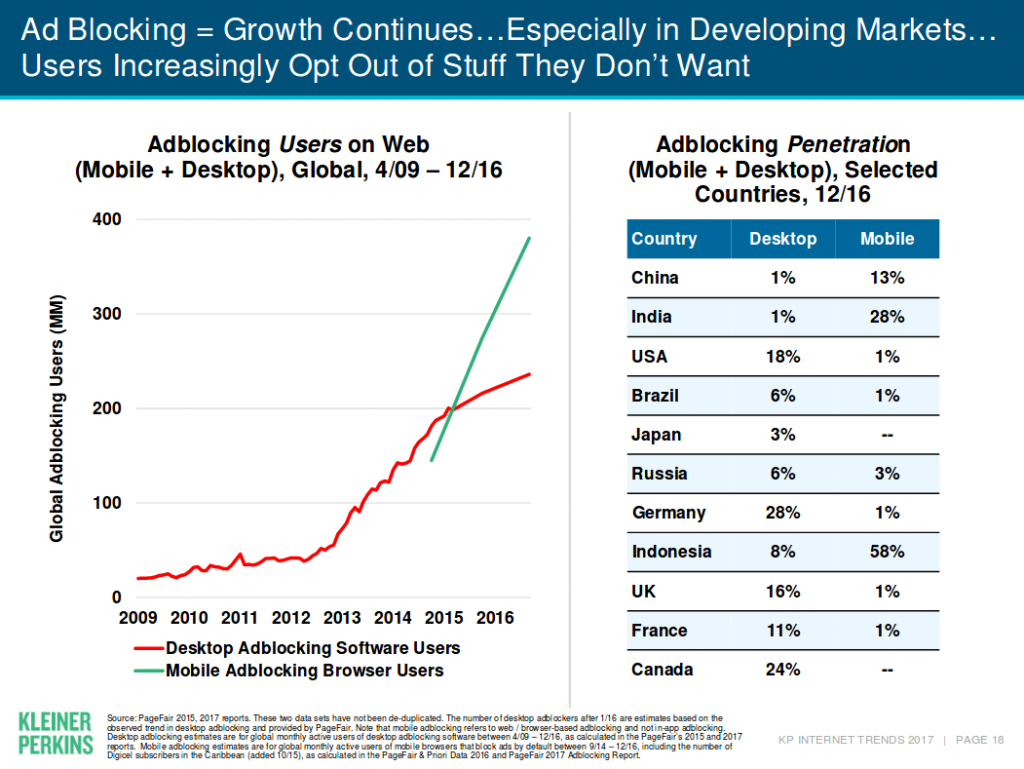
Het blijkt erg lastig om controle te krijgen over je persoonlijke digitale data spoor dat je achterlaat op het world-wide-web. Daarom maken veel sociale-media bezoekers gebruik van Ad-Blockers (Wired, 2019). Zelfs end-to-end dataversleuteling van WhatsApp blijkt gevoelig voor tracking door het lekken van data (VPNGids.nl, 2019). Meer recent blijkt het ook onbeschermd tegen spyware (Financial Times, 2019;Wired, 2019).
Niet alleen je individuele browser & sociale media activiteit wordt digitaal vastgelegd. Ook wat je doet op de meer professioneel georiënteerde collaborative platforms zoals Yammer, Slack & Trello blijken lekgevoelig voor persoonsgegevens. Vooral Trello-boards zijn eenvoudig vindbaar via the Google zoekmachine en deze blijken persoonsgegevens te bevatten die niet zijn versleuteld (NRC, 2019).
Een zeer recente vorm van tracking is —Sensor Calibration Fingerprinting for Smartphones— waarbij gebruik wordt gemaakt van ——Device Fingerprinting Attack-—.
Woman in Data Computing
The lack of sustained gender and ethnic participation persists in computing.
Media images produce mental models of who participates and what participation even looks like.
One common image is that men can be ordinary while women must be exceptional, and women of color must be better than exceptional.
Doing the Right Things
A Quest of making Human-Centered Sense of Data
Het hier beschreven krachtenveld van hoe data anno 2019 bepalend is voor onze platformeconomie en breed maatschappelijke ontwikkelingen —zoals het beschermen van persoonsgegevens, klimaatverandering en het gebruik van AI— laat zien dat het opleiden van CMI studenten —om professioneel, betekenisvol & ethisch verantwoord met data om te kunnen gaan— deskundige begeleiding vereist in combinatie met praktijkgericht onderzoek vanuit CMI en het kenniscentrum Creating 010.
Uitgangspunt hierbij is dat de doorsnee burger niet het slachtoffer wordt van een ongebreidelde stroom aan “gratis online diensten”, verzamelde big-data en de uitwerking van AI computer algoritmen met behulp van IoT infrastructuur zonder tussenkomst van enige vorm van controle door mensen.
Te denken valt aan de recente ontwikkelingen rondom het fenomeen “Fake News & Sociaal krediet”. Dit is mede veroorzaakt door de controversiële berichtgeving rondom de presidentiële verkiezingen van de Verenigde Staten in 2016 en de verspreiding ervan via Facebook. Hetzelfde geldt voor het BREXIT-referendum in de UK in dat zelfde jaar (Trouw, 2017).
Toch zullen maar weinigen uitleg kunnen geven aan waar “Fake News” nu voorstaat en wat haar relatie is met “Big Data”. De Newsweek cover story van juni 2017 getiteld: “How Big Data Mines Personal Info to Craft Fake News and Manipulate Voters” maakt duidelijk het disruptieve karakter van een overdadig gebruik van smartphones in combinatie met het gedogen van ongebreidelde “Big Data Mining” via het IoT. Dit overdadige sociale-media gebruikt maakt het mogelijk dat Russische trollen kunnen inspelen op westerse angsten. Rusland heeft in de aanloop naar het Brexit-referendum ruim 156.000 twitter-accounts ingezet in een poging de stemming te beïnvloeden. De accounts, vooral ‘bots’ oftewel robot profielen die automatisch tweets rondpompen, hebben in de 48 uur voor de stembusgang 45.000 berichten verstuurd (The Guardian, 2018). Tegenover deze door de burger self-inflicted fake-news crisis, staat het fenomeen Sociaal Krediet Score gebaseerd op Sesam Krediet van internet handelshuis Alibaba (2015).

Het basisidee van een sociaal kredietscore is: door middel van het verzamelen en analyseren van grote hoeveelheden digitale informatie iedere burger, ieder bedrijf en iedere overheidsdienst punten toe te kennen. De invoering van een sociaal kredietscore is volgens het Chinese politbureau uiteraard ingegeven door de beste bedoelingen, namelijk het bestrijden van de ‘eerlijkheidscrisis’: “Laat de betrouwbaren vrijelijk bewegen onder de hemel, terwijl de onbetrouwbaren worden belemmerd om ook maar één stap te zetten”, vertaalde het Volksdagblad het jargon van president Xi Jinping in 2016.
Human-Centered Principles
De hier beschreven cyberspace problematiek van het digitale platform tijdperk vereist hernieuwde aandacht voor Bildung van hbo studenten als kenniswerkers: Hoe leren HBO’ers om maatschappelijk relevante data inzichtelijk en ethisch verantwoord te delen; gegeven het disruptieve karakter van de alomtegenwoordigheid aan “Smart Things” en de daaruit voortvloeiende caleidoscopische berg aan “Big Data”?
Met alleen professionele begeleiding en praktijkgericht onderzoek komen we er niet. CMI studenten zullen ook de kans moeten krijgen om zelf ervaring op te doen met het verzamelen van big data met behulp van IoT oplossingen en de analyse ervan door gebruikmaking van cloud-based AI services: learning-by-doing.
Didactische Kwaliteiten CMI
Het innovatieve karakter van het Human-Centered Data-Lab project ligt dan ook besloten in de vraag hoe Artificial Intelligence (AI) —-in de vorm van Machine learning (ML), Natural language Processing (NLP) & Computer vision (CV)— kan worden ingezet binnen een onderwijssetting om te komen tot Bildung enerzijds en het laagdrempelig, verantwoord delen van inzichten voor maatschappelijke vraagstukken die voortvloeien uit het op grote schaal uitvoeren van “Big Data Mining”, anderzijds.
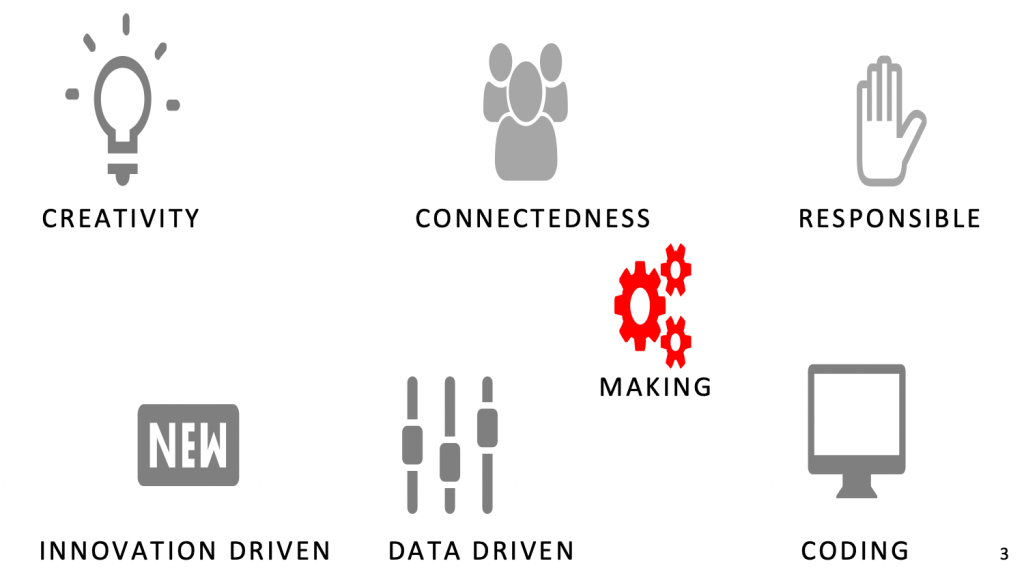
De collectieve overtuiging binnen CMI is dat de verschillende opleidingen —COM, CMD, CMGT, INF, TI— ieder voor zich een unieke mengeling van aan data-gerelateerde didactische kwaliteiten herbergt om zo inhoud te kunnen geven aan het Human-Centered Data-Lab, deze zijn: creativity, connectedness, responsible, innovation-driven, data-driven, coding & making.
Visual Hub & data Showcases
De fysieke verschijningsvorm van het Human-Centered Data-Lab krijgt de gestalte van een Visual Hub. Doel is om interactieve data showcases overal in het CMI-gebouw toegankelijk te maken, zowel in de klassieke klassikale omgeving als ook binnen de lab-setting van het Stadslab Rotterdam. Zie Plan van Aanpak.
Open-Badges, EduID, EduBadges/Backpacks & EduMij
Het HC-DATA Lab maakt gebruik van Digital (Open) Badges om extra curriculair onderwijs mogelijk te maken (Open-Badges). Een open badge is een visueel, digitaal en betrouwbaar bewijs van een vaardigheid of competentie die je hebt verworven. Open Badges maken het eenvoudig om:
- Erkenning te krijgen voor skills die studenten leren,
- Erkenning te geven voor datgene wat docenten & private opdrachtgevers doceren,
- Vaardigheden, herkomst en echtheid ervan te kunnen verifiëren, en
- Geverifieerde badges via een digitaal platform te beheren.
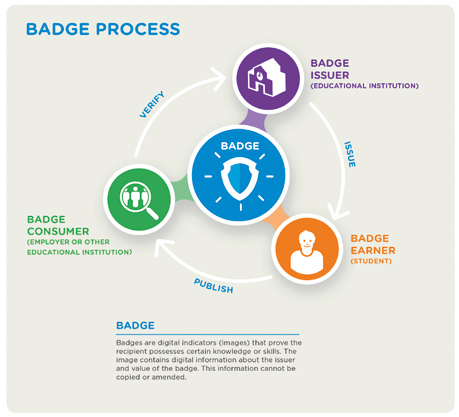
In Nederland onderzoekt SURF —een Nederlandse ICT-coöperatie voor onderwijs en onderzoek— of één student-identiteit, een digitaal eduID, kan helpen om de wensen van onderwijsinstellingen, opleidingen en studenten te realiseren (SURF.nl, 2019). Meer in het bijzonder, SURF onderzoekt de voordelen van een eduID in een pilot waarin studenten ‘badges’ krijgen uitgereikt voor kennis of vaardigheden die zij hebben aangetoond.
Deze eduBadges maken gebruik van een eduID om de student uniek te identificeren en zo de behaalde resultaten aan de student te koppelen en – op termijn – bijvoorbeeld via EduMij te bundelen. Het EduMij zorgt er dan voor dat een student al zijn behaalde onderwijsresultaten en diploma’s in een digitaal portfolio kan verzamelen door gebruik te maken van de unieke eduID identiteit. EduMij is een initiatief van het ministerie van OCW dat momenteel door DUO, SURF en de koepels wordt uitgewerkt. Het is geïnspireerd op MedMij, https://www.medmij.nl/.

{kind=link}